The dataset consists of modern documents and archival ones with various formats, including document images and born-digital formats such as PDF. The annotated contents contain the table entities and cell entities in a document, while we do not deal with nested tables. We gathered 1000 modern ones and 1000 archival ones as table region detection task's test dataset and 80 documents as table recognition task's test dataset (see figure examples below).
The samples can be downloaded here.
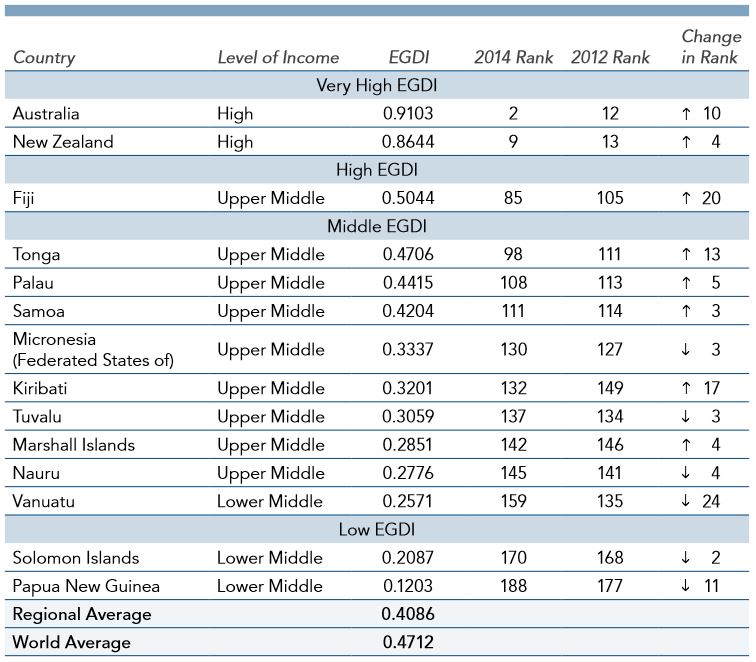
Figure (a) : modern dataset
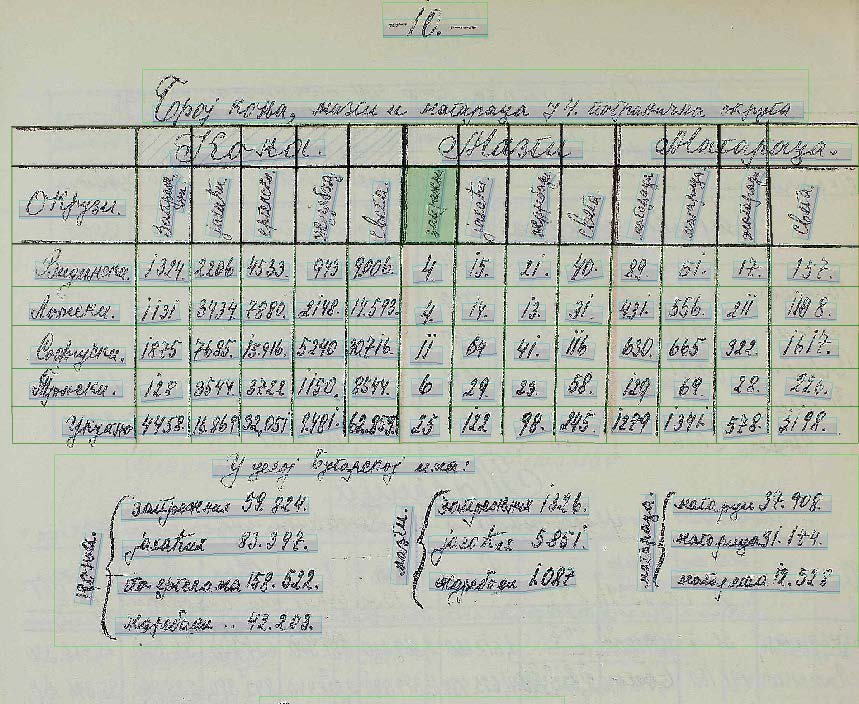
Figure (b) : historical dataset
For the annotation of dataset, we use an similar notation derived from ICDAR 2013 Table Competition format, creating a single XML file to store the structures.
In the XML file. Each <table> element corresponds to a table, which contains a single <Coords> element with [points] attribute to indicates the coordinates of the bounding polygon with 4 vertices. Table also contain a list of <cell> elements, for each <cell> element attributes [start-row], [start-col], [end-row] and [end-col] denotes its position in the table, and a unique numerical [id] for this cell.The element <Coords> for the <cell> element denotes the coordinates of the bounding polygon of this cell box, and <content> is the text within this cell (optional for submission).
<?xml version="1.0" encoding="UTF-8"?>
<document filename="table.jpg">
<table>
<Coords points="92,442 92,528 350,528 350,442"/>
<cell start-row="0" start-col="1" end-row="0" end-col="1">
<Coords points="154,442 154,453 200,453 200,442"/>
<content>IndustryA</content>
</cell>
...
<cell start-row="4" start-col="4" end-row="4" end-col="4">
<Coords points="334,517 334,528 350,528 350,517"/>
<content>660</content>
</cell>
</table>
...
<table>
<Coords points="414,442 414,528 673,528 673,442"/>
<cell start-row="0" start-col="1" end-row="0" end-col="1">
<Coords points="477,442 477,453 522,453 522,442"/>
<content>IndustryB</content>
</cell>
...
</table>
...
</document>
Important Note: For the modern dataset, the convex hull of the content describes a cell region. For the historical dataset, it is requested that the output region of a cell is the cell boundary. This is necessary due to the characteristics of handwritten text, which is often overlapping with different cells.
Update Note: A novel supplement dataset version is published in ICDAR2019_cTDaR_dataset_supplement, which is a helpful subset in terms of adjacency relations, from Prof. Cheng-Lin Liu's Group, Institute of Automation, Chinese Academy of Sciences. Thank Cheng-Lin Liu's Group for their helpful contributions!